Having fast optimization algorithms,having good optimization algorithms can reallyspeed up the efficiency of you and your team.Vectorization allowsyou to efficiently compute on all m examples,that allows you to process your whole training set without an explicit For loop.
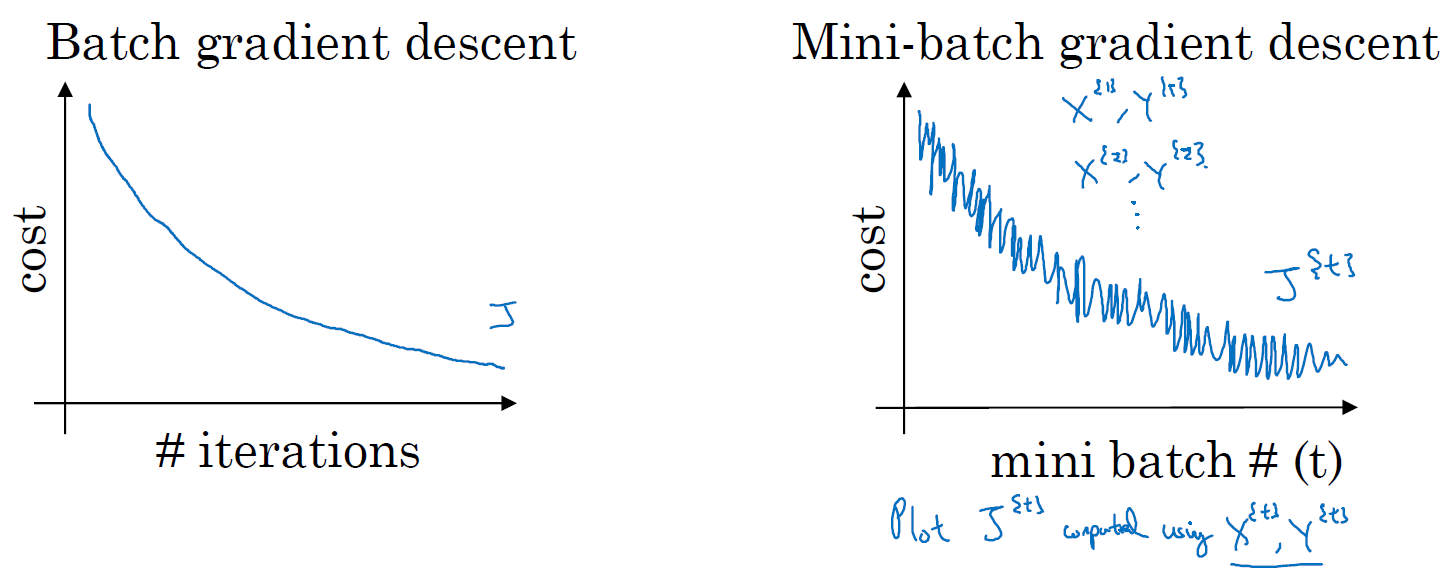
2. Understanding Mini-Batch gradient descent
Cost(loss) function
source : Deeplearning.AI
잘못 라벨링된 데이터가 섞여 있는 batch의 경우에는 큰 loss 값을 가질 수 있고 batch마다 loss 값이 일정하지 않으므로 그래프에서 jittering이 발생한다.
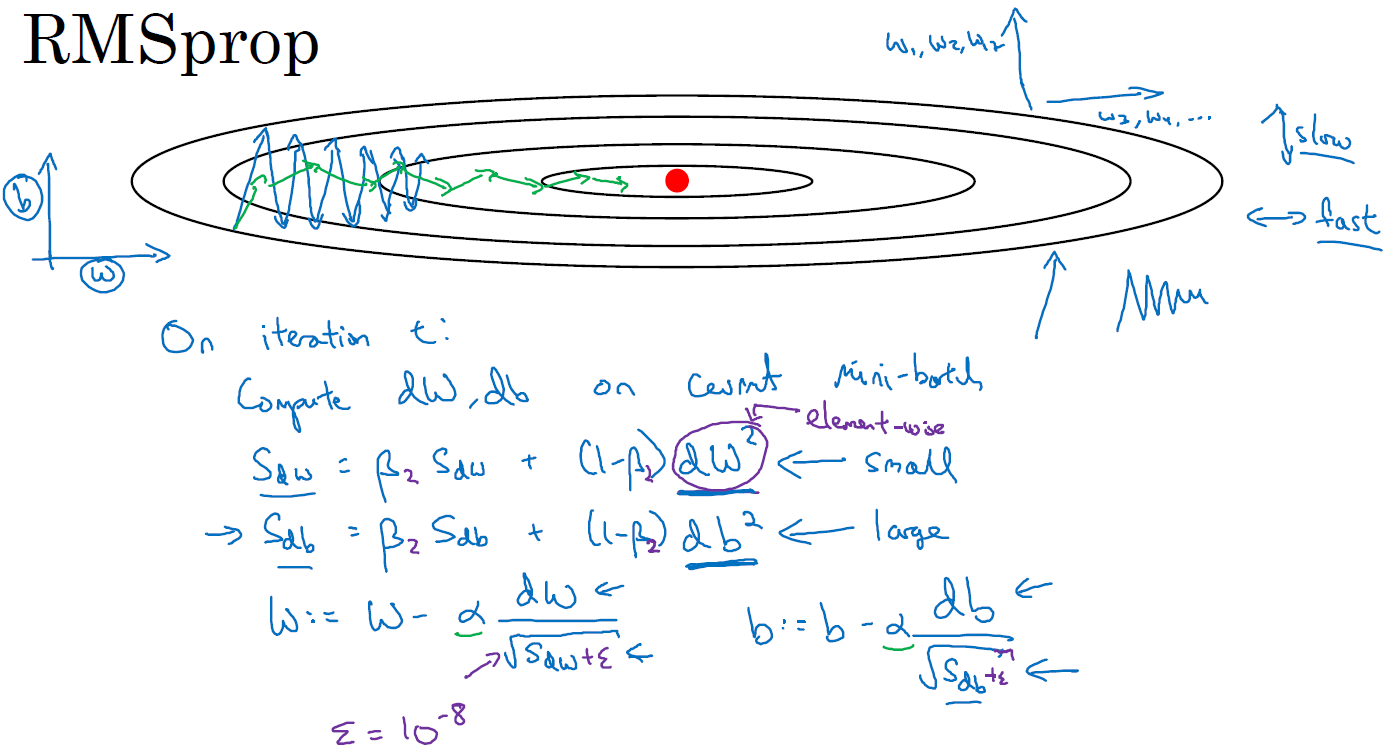
Choosing mini-batch size
source : Deeplearning.AI
batch가 여러개인 경우에는 각 iteration마다 너무 많은 시간이 걸리고, batch size가 1인 경우(Stochastic Gradient Descent)에는 훈련 속도가 너무 오래걸린다(lose speedup from vecterization). 따라서 적당한 batch size를 찾아야한다.
Tip1. If small training set(m<=2000) : use batch gradient descent
Tip2. Else, because of the way computer memory layed out and accessed, your code runs faster if your mini-batch size is a power of 2. (64, 128, 256, 512, 1024)
Tip3. All of your X{t}, Y{t} that that fits in CPU/GPU memory.
batch gradient descent에 대한 정의가 조금 헷갈렸었는데, batch gradient descent는 전체 데이터셋에 대해 loss를 구하고 기울기를 한 번만 update 하는 방식이다. 아래 사이트에서 BGD의 장단점을 읽어보면 쉽게 이해할 수 있다. https://light-tree.tistory.com/133










댓글