📜 강의 정리
* Cousera 강의 중 Andrew Ng 교수님의 Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and Optimization 강의를 공부하고 정리한 내용입니다.
* 영어 공부를 하려고 부분적으로 영어로 강의를 정리하고 있습니다. 혹시 틀린 부분이나 어색한 부분이 있다면 댓글로 알려주시거나 넘어가주시면 감사하겠습니다
Setting Up your Machine Learning Application
1. Train/dev/test

- ratio of each part
- (Small dataset) Trainng : Validation : Testing = 60 : 20 : 20
- (Large dataset) Training : Validation : Testing = 98 : 1 : 1 or 95 : 2.5 : 2.5
Regularizing your Neural Network
1. Regularization
There is two ways to prevent high variance problems. One of the first thing is to try regularization and the other thing is to get more trainig datas.
- How regularization work?
- Regularization term is added to loss function. There are L1 regularization and L2 regularizaton, L2 regularization is just used much much much more often.

- L2 regularization is also called "Frobenius norm". It means the sum of square of elements of a matrix
- Neural Network
-

- λ/m*w_l is added to dw_l. It is derivative of l2-regularization.
2. Why Regularization Reduces Overfitting?

The regularization term(purple part) pernalize the weight matrices from being too large.
For example, let's suppose we use a tanh function as an activation function.W value is close to zero if lambda is big number because the cost function J should be close to zero. Tanh function has linear slope in the scope near zero, but it has smooth slope away from the zero.비용함수는 값이 작아져야하기 때문에 람다를 큰 수로 하면 W는 0에 가까워져야 한다. z = wx+b 에서 w가 0에 가까워지면 z도 0에 가까워지게 된다. z는 tanh(활성함수)의 input이 되는데, tanh의 경우 0 주변의 기울기는 linear function에 가까워서 상대적으로 전체적인 함수가 linear하게 되며 심플해지는 효과가 발생한다.
여기서 궁금한 점은 tanh가 아니면 regularizationn 효과가 있나? 이런 생각이 든다. ReLU에도 적용이 되는건가?
3. Dropout Regularization
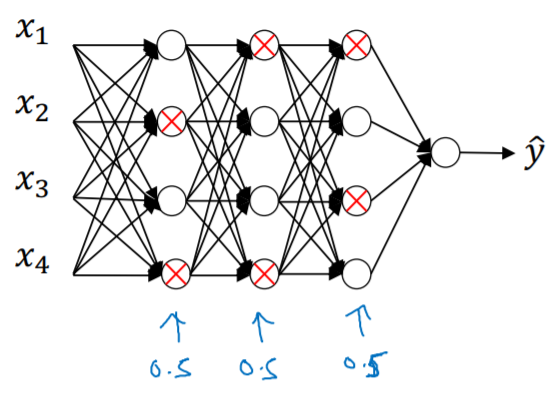
Dropout is to set some probability(here 0.5) of eliminating a node in neural network. We are going to keeping or removing each node with a probability of 0.5.
4. Understanding Dropout
Why does dropout work?
Intuition : Can’t rely on any one feature, so have to spread out weights. Shrink weights

Notice that you should set different keep.probs for different layers, you should avoid to use dropout at the input layer and the classifier layer(=keep probability with 1.0).
In computer vision, the input sizes is so big in putting all these pixels that you almost never have enough data. And so dropout is very frequently used by the computer vision and there are some common vision research that dropout is pretty much always used as a default.
5. Other Regularization Methods
- Data augmentatio

- Early stopping

Setting Up your Optimization Problem
1. Normalizing Inputs

2. Vanishing/Exploding Gradients
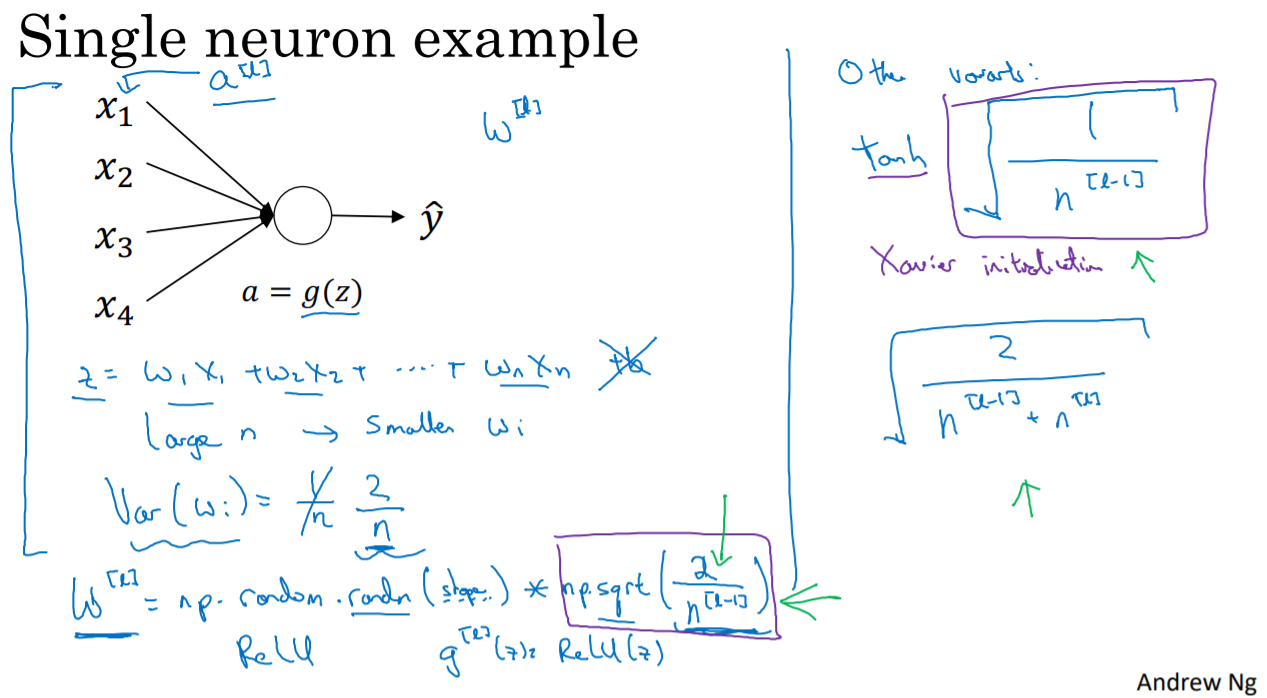
3. Weight Initialization for Deep Networks
The way you initialize weight depends on activation function.
4. Numerical Aprroximations of Gradients




댓글