목차
1. 강의정리
1-1. Pytorch - chap8. Multi GPU
1-2. Pytorch - chap9. Hyperparameter tuning
1-3. Pytorch - chap10. Pytorch Troubleshooting
2. 피어세션 정리
3. 데일리 회고

📜 강의 정리
* 부스트캠프 PyTorch 강의를 맡아주신 최성철 교수님의 강의를 정리한 것 입니다.
[Pytorch] Chapter8. Multi GPU
학습시킬 데이터 양이 방대해지면서 한 대의 컴퓨터(node), 한 개의 GPU만으로는 부족하다
다중 GPU에 학습을 분산시키는 방법은 모델을 나누는 방법(Model Parallel)과 데이터를 나누는 방법(Data Parallel)이 있다.
1. Model Parallel
- AlexNet에서 볼 수 있듯이 모델을 나누는 방식을 예전부터 사용했다.

- sub_model_1.to(cuda:0), sub_model_2.to(cuda:1) : .to(device)로 각 다른 GPU에 할당한다
- 모델의 병목과 파이프라인의 어려움으로 모델 병렬화는 고난이도 과제다
2. Data Parallel
- 데이터를 나눠서 여러 GPU에서 계산한 후 평균을 취하는 방식 - minibatch와 유사
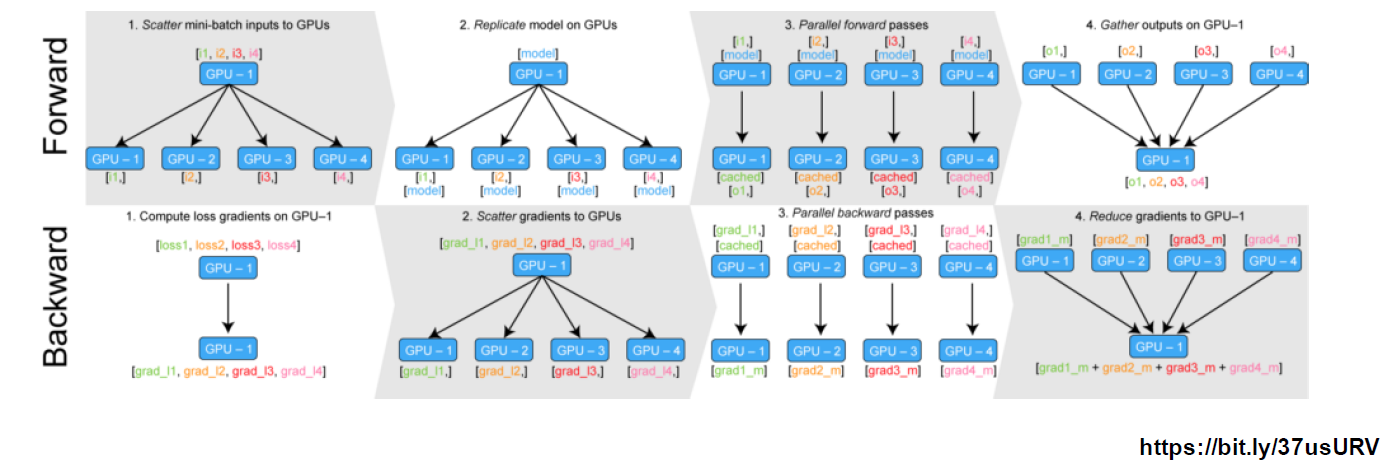
코디네이터 gpu가 일이 많아지는 단점 - 방법 1) DataParallel : 단순히 데이터 분배 후 평균 계산
- 한 GPU에서 결과를 취합하는 과정이 필요하기 때문에 GPU 사용량이 불균형하고 Batch size를 감소시켜야 한다
- parallel_model = torch.nn.DataParallel(model) # 코드 이게 전부
- 방법 2) DistributedDataParallel
- 분배한 데이터마다 GPU뿐 아니라 CPU도 하나씩 분배하여서 분배된 데이터셋 내에서 backward 계산을 한다.
- sampler를 사용한다. num_worker는 보통 gpu 개수의 4배를 사용한다
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data) shuffle = False pin_memory = True trainloader = torch.utils.data.DataLoader(train_data, batch_size=20, shuffle=False pin_memory=pin_memory, num_workers=3, shuffle=shuffle, sampler=train_sampler)
[PyTorch] Chapter9. Hyperparameter Tuning
학습 성능을 높이기 위한 주요 요인으로는 모델, 데이터, 하이퍼파라미터가 있다.
기본적인 방법으로는 grid, random 방식으로 하이퍼파라미터를 추출하는 방법이 있고, 최근에는 베이지안 기법들이 주도 하고 있다.
1. Ray : 대표적인 하이퍼파라미터 튜닝 도구
- multi-node multi processing 지원
- ML/DL 병렬처리 지원
- 하이퍼파라미터 서치를 위한 다양한 모듈 지원
## search space 지정 data_dir = os.path.abspath("./data") load_data(data_dir) config = { "l1": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)), "l2": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)), "lr": tune.loguniform(1e-4, 1e-1), "batch_size": tune.choice([2, 4, 8, 16]) } ## 학습 스케줄링 지정 scheduler = ASHAScheduler(metric="loss", mode="min", max_t=max_num_epochs, grace_period=1, reduction_factor=2) ## 결과 출력 양식 지정 reporter = CLIReporter(metric_columns=["loss", "accuracy", "training_iteration"]) ## 병렬처리 양식으로 학습 실행 result = tune.run(partial(train_cifar, data_dir=data_dir), resources_per_trial={"cpu": 2, "gpu": gpus_per_trial}, config=config, num_samples=num_samples, scheduler=scheduler, progress_reporter=reporter)
[PyTorch] Chapter10. Pytorch Troubleshooting
🌈OOM - Out Of Memory - 예방책 및 해결책에 대해 알아보자
OOM은 어디서 발생했는지, 왜 발생했는지 파악하기 어렵다.
일반적인 해결책 : OOM이 발생 → Batch 사이즈 줄이기 → GPU clean → Run
위의 방식으로 해결 안된다면.. 다음 방법들을 사용해보자.
1. GPUUtil
- GPU 상태 보여주는 모델
-
!pip install GPUtil import GPUtil GPUtil.showUtilization() # iter마다 메모리 느는지 확인
2. torch.cuda.empty_cache() 써보기
- GPU에서 사용되지 않는 cache 정리
3. trainning loop에 tensor로 축적 되는 변수는 확인할 것
- tensor는 GPU에 올라가므로, 한 번 사용하는 1-dimensional tensor의 경우는 python 기본 객체로 사용
- float이나 .item 사용하면 변환 가능
4. del 명령어 적절히 사용하기
- python에서는 loop 끝나도 메모리가 삭제되지 않음
5. 가능한 batch size 실험해보기
- batch size 최대 크기 구하기
oom = False try: run_model(batch_size) except RuntimeError: # Out of memory oom = True if oom: for _ in range(batch_size): run_model(1)
6. torch.no_grad() 사용하기
- backward pass 에서 쌓이는 메모리에서 자유로움
- inference 시점에서는 torch.no_grad() 사용

🙋♀️피어세션
https://luck-tuberose-cf9.notion.site/2021-08-20-3-79e6623239d04c85976468a74fee7a3d
피어세션(2021/08/20) - 3주차 팀 회고록
0. 랜덤피어세션은 어땠나요?
luck-tuberose-cf9.notion.site
💌 데일리 회고
한 주 동안 부족했던 점들이 많아서 주말에는 공부하고 싶은 것들을 공부하고 싶은데, 가족 휴가를 가게 되었다.. 분명 놀러가는 건데, 공부할게 많아서 그런지 집에서 공부 하고 싶다😥 이왕 가게 된 거 기쁜 마음으로 리프레쉬 하고 와서 다음주에 열정 쏟아야겠다🔥
'TIL > Boostcamp AI tech' 카테고리의 다른 글
| [Boostcamp]Data visualization Seaborn :: seoftware (0) | 2021.08.24 |
|---|---|
| [Boostcamp]Week4-Day15. P stage start :: seoftware (0) | 2021.08.23 |
| [Boostcamp]Week3-Day13. Pytorch 모델 불러오기 :: seoftware (0) | 2021.08.19 |
| [Boostcamp]Week3-Day12. Pytorch 구조 학습 :: seoftware (0) | 2021.08.18 |
| [Boostcamp] week3-Day11. Pytorch 기본 :: seoftware (0) | 2021.08.17 |




댓글