Multi-modal learning이란 한 타입의 데이터가 아니라 다른 특성을 갖는 데이터 타입을 같이 활용하는 학습법. 예를 들면, 텍스트와 사운드 함께 학습하는 예시가 있다.
1. Overview of Multi-Modal learning
✔ multi-modal의 어려운 점(Challenge)
Different representations between modalities : 데이터 간의 표현 방법이 다르다. 오디오는 1-d signal의 wave form. 이미지는 2d, 3d array. 텍스트는 워드에 해당하는 embedding data.
Unbalance between heterogeneous feature spaces : 한 이미지에 해당하는 텍스트가 한 개가 아니다(1:N 매칭). 예를 들면 "아보카도 모양의 암체어를 찾아줘"라는 텍스트에 대해 해당하는 이미지가 여러가지가 있고 반대의 경우도 여러가지로 표현이 가능하다.
May a model be biased on a specific modality : 오히려 많은 정보가 학습에 방해가 될 수 있다. 대부분의 이미지로 로 예측이 가능하기 때문에 한 데이터 타입으로 모델이 biased되는 경향이 있다.
✔Despite the challenges, multi-modal learning is fruitful and important
다양한 구조의 multi-modal
2. Multi-Modal Task (1) - Visual data & Text
✔ Text data에 대한 기초
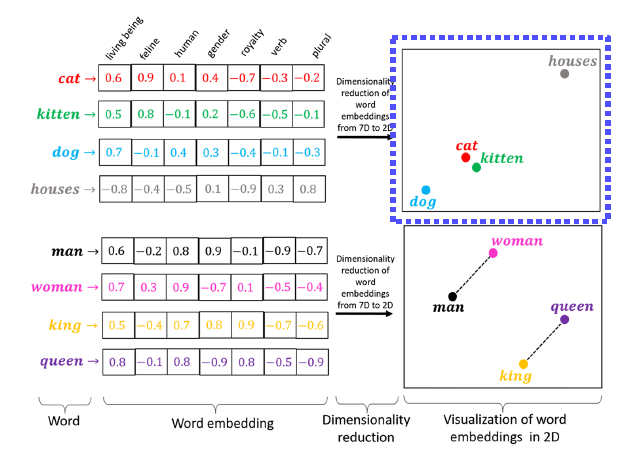
Text Embedding
Embedding Dense vector로 표현(verb, plural 등의 특징을 벡터로 표현)
Text embedding vector간의 관계특성이 들어가고 일반화가 가능하다. 위의 이미지를 보면 cat과 kitten이 가깝고 cat에는 dog가 house보다 가깝게 위치한다. 남자와 여자의 관계가 king과 queen의 관계와 같은 걸로 볼 수 있다.
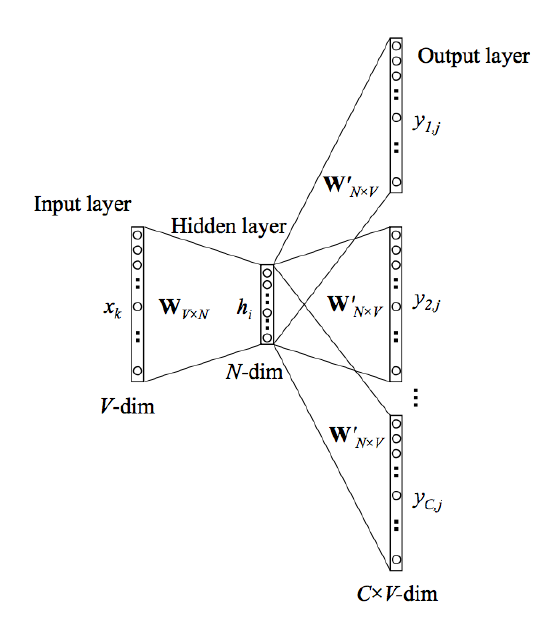
word2vec - skip gram model
text embedding을 사용하는 방법
W와 W'을 학습한다
W의 행벡터는 각 word의 embedding vector이다.
skip-gram model
각 워드의 앞, 뒤 등의 문장 패턴을 학습하는 모델
주변 N개의 word를 예측하고, 그 단어 주변의 단어들과의 관계성을 이해한다.
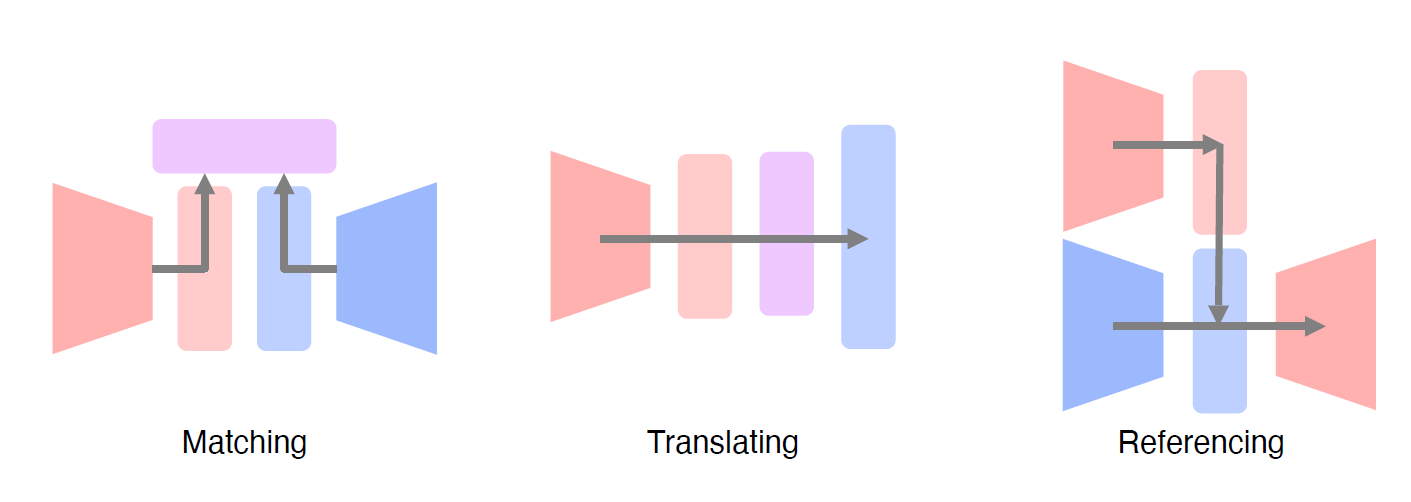
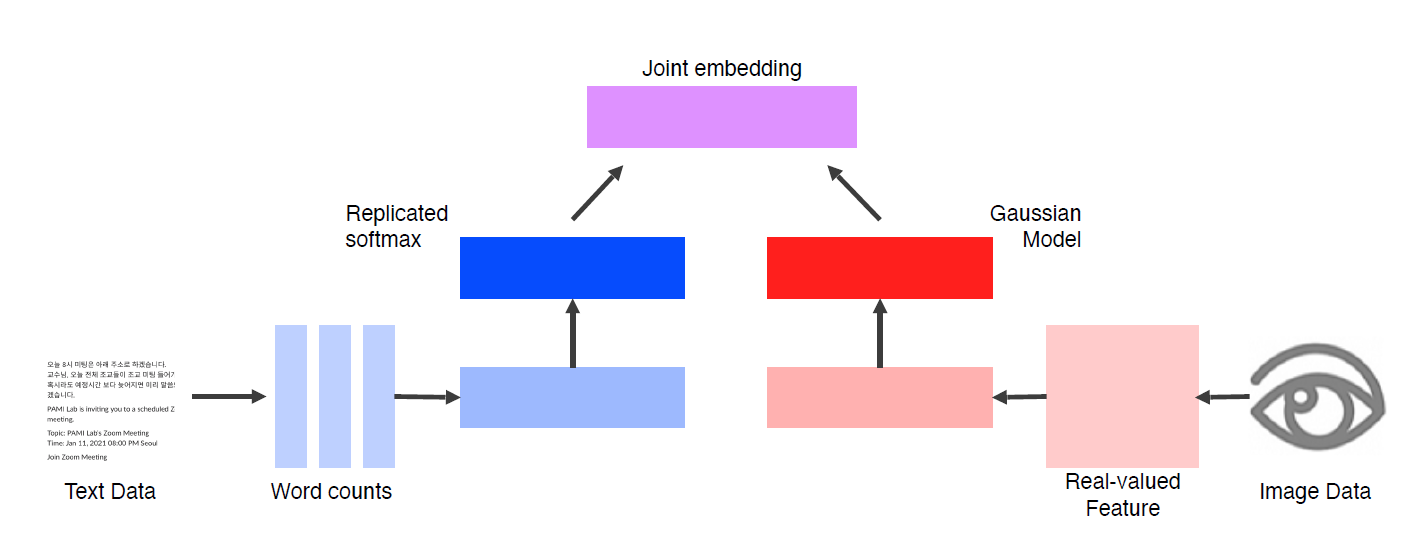
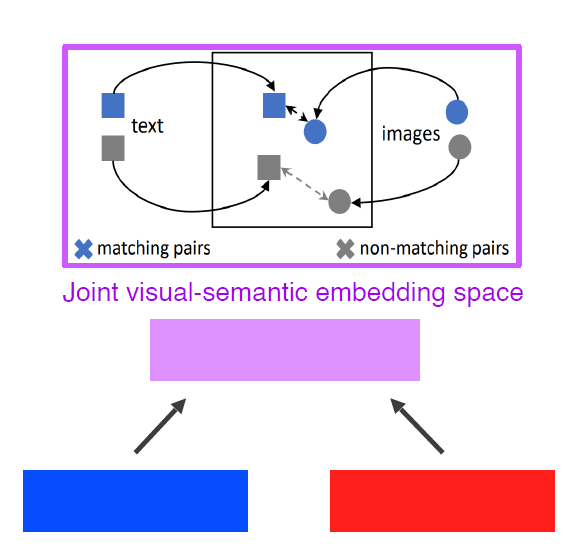
✔ Joint Embedding
매칭을 하기 위한 Embedding vector를 학습하는 방법
1. Image Tagging : 이미지를 보고 태그를 추천해주거나, 태그를 보고 이미지를 생성한다
두 pretrained uni-modal models를 combine
Metric learning : 같은 embedding space에 mapping을 해주고, 두 distance간의 거리를 push(멀게) 해야할지 pull(가깝게) 해야할지 학습한다.
2. Cross Modal Translation
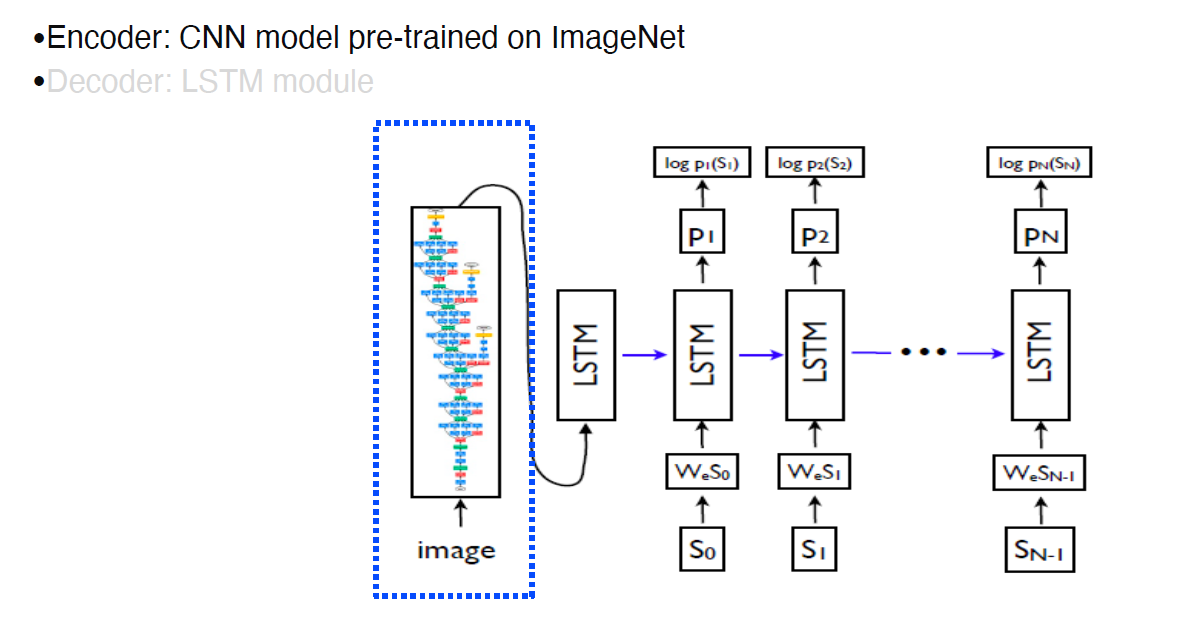
Image Captioning : Image to Sentence 이미지를 설명하는 텍스트로 변환
이미지는 CNN & 텍스트는 RNN : show and tell
Show: Encoder, Tell : Decoder
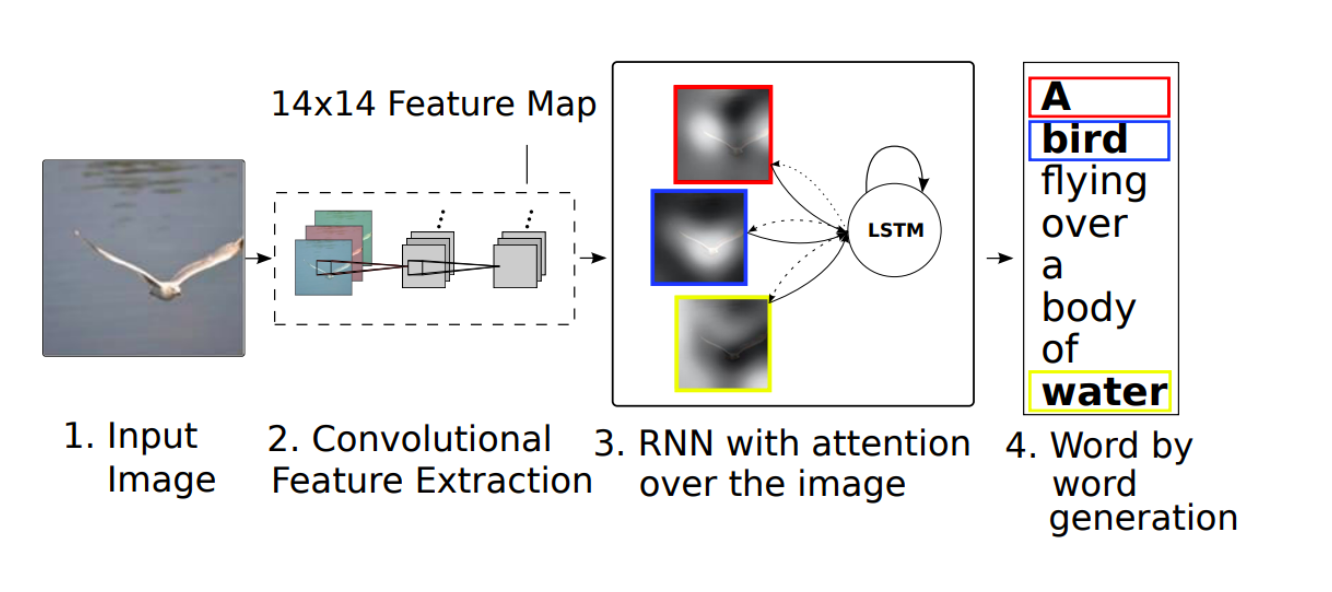
Show, attention(attend), tell : 어떤 feature가 어떤 text로 변환되는지 집중
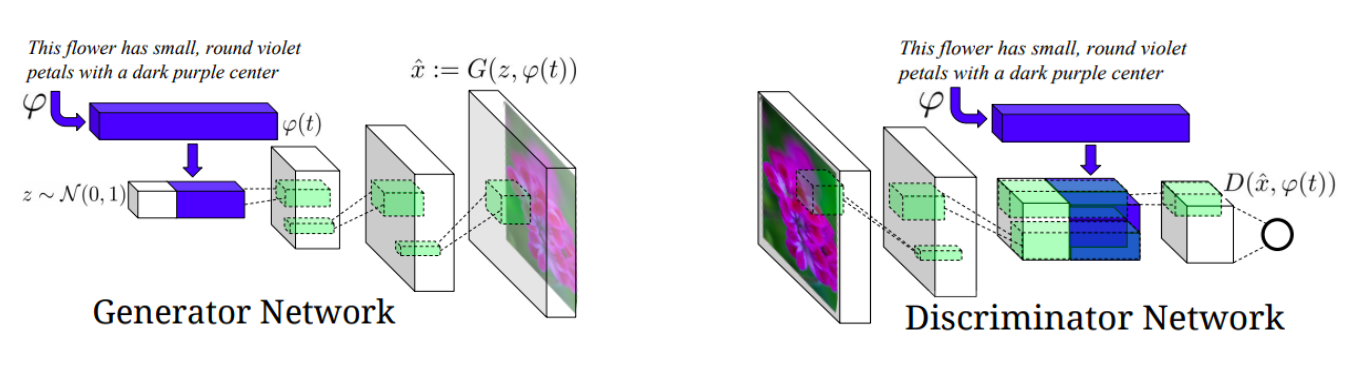
Text를 Image로 주어지는 경우에는 아래와 같이 여러 이미지가 나오므로 generative model을 사용해야 한다.
가우시안 랜덤코드(z~N(0,1))는 똑같은 랜덤코드가 들어갔을 때, 항상 다른 이미지가 나올 수 있도록 해준다.
3. Cross Modal Reasoning(Referencing)
Visual question answering : 이미지를 보고 질문에 대답을 하는 것. end-to-end training
3. Multi-Modal Task (2) - Visual data & Audio
✔ Sound Representation
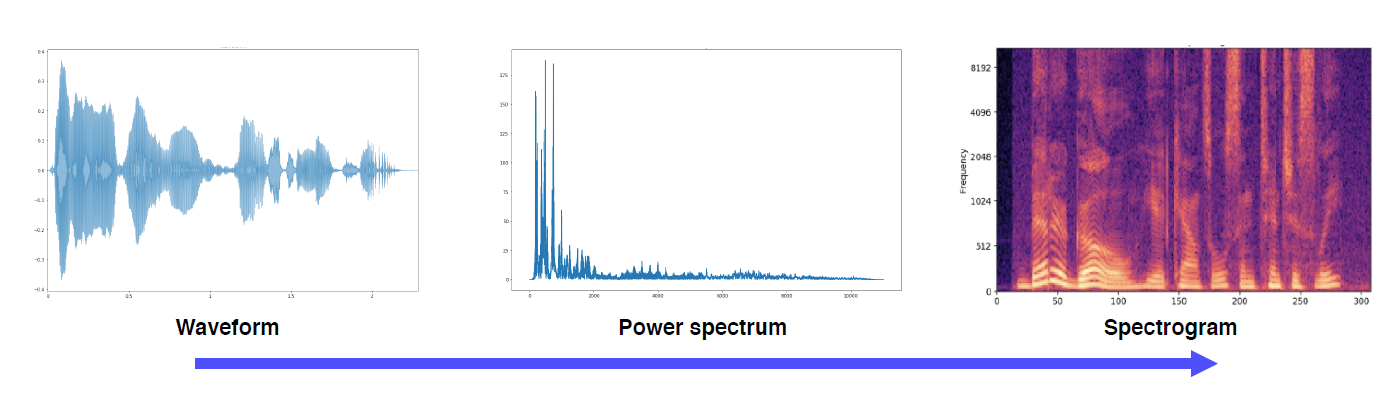
Waveform을 Spectrogram으로 변환하여 사용한다. 변환방법으로 푸리에변환(Fourier transform)을 사용하는데, 시간적인 정보를 담기 위해 Short-time Fourier transform (STFT)를 사용한다.
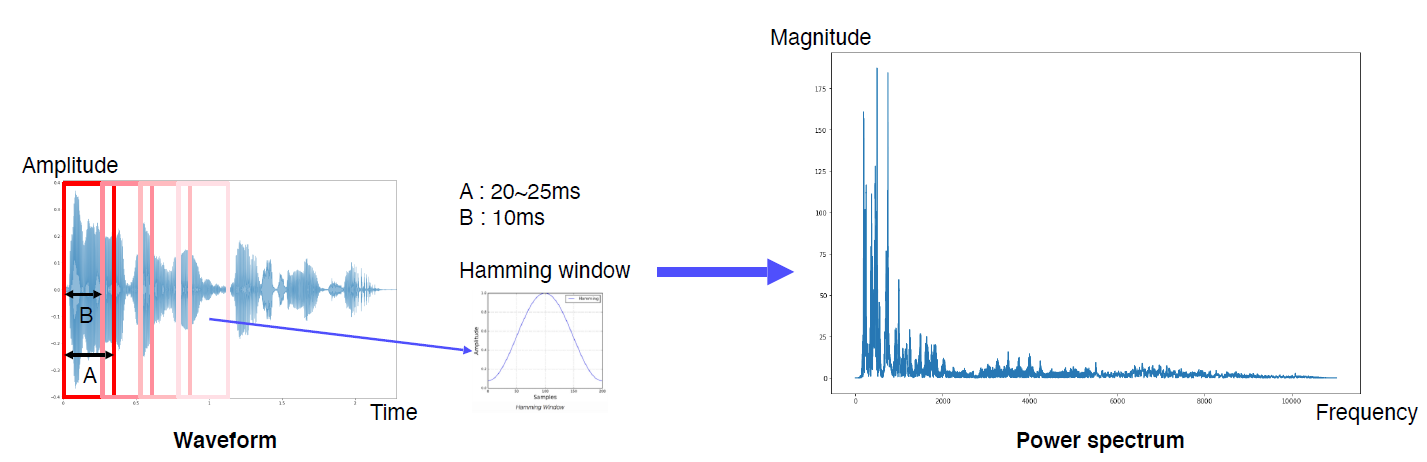
Short-time Fourier transform (STFT)이란 특정 사이즈의 윈도우를 waveform 위에서 이동시키며 푸리에 변환을 적용하는 방법이다.
푸리에 변환을 하게 되면 정규분포 모양의 결과물이 나오는데, 그걸 윈도우 단위별로 적용하여 시간에 따른 푸리에 변환을 확인할 수 있게 된다. 또한 Hamming window를 window와 element wise 곱을 해서 가운데 영역의 feature를 더 두드러지게 표현하도록 한다.
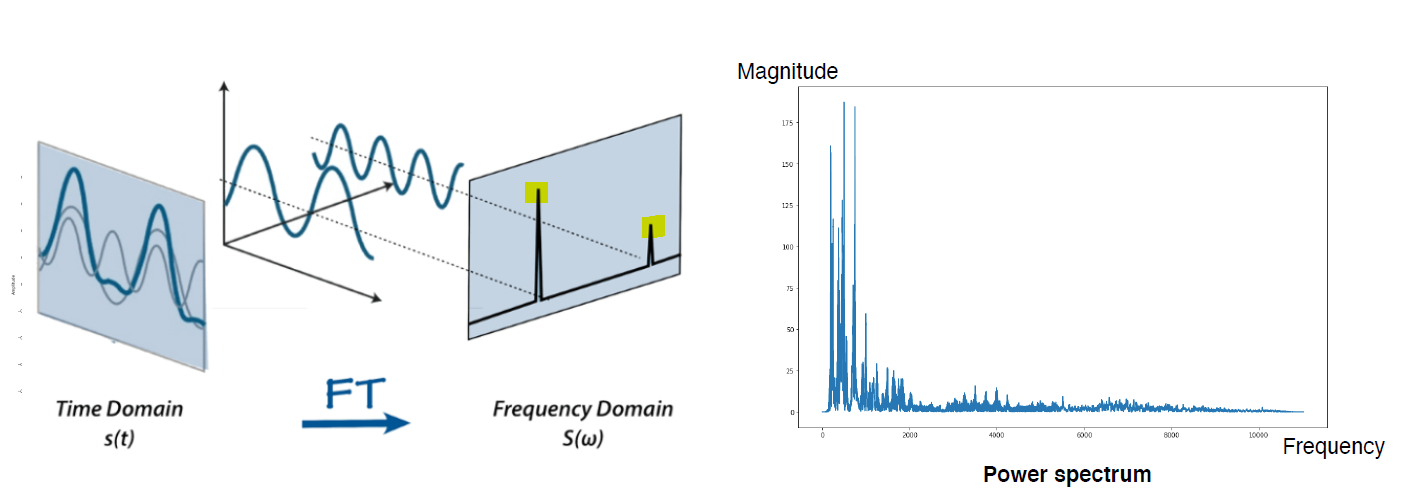
Fourier transform을 하는 이유는 주파수 특징을 파악할 수 있도록 하기 위해서이다. 아래 사진을 보면 Frequency Domain의 특징이 다른 것을 확인할 수 있다.
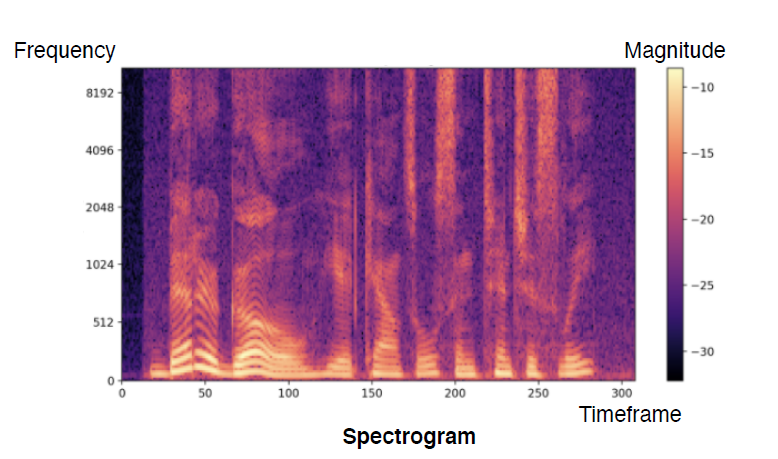
결과적으로 타임축에 따른 spectrum의 stacking을 통해 아래와 같은 spectogram이 만들어져서 nueral network의 인풋이미지로 사용된다. MFCC, melspectogram등의 표현 방식이 있다.
✔ Joint Embedding
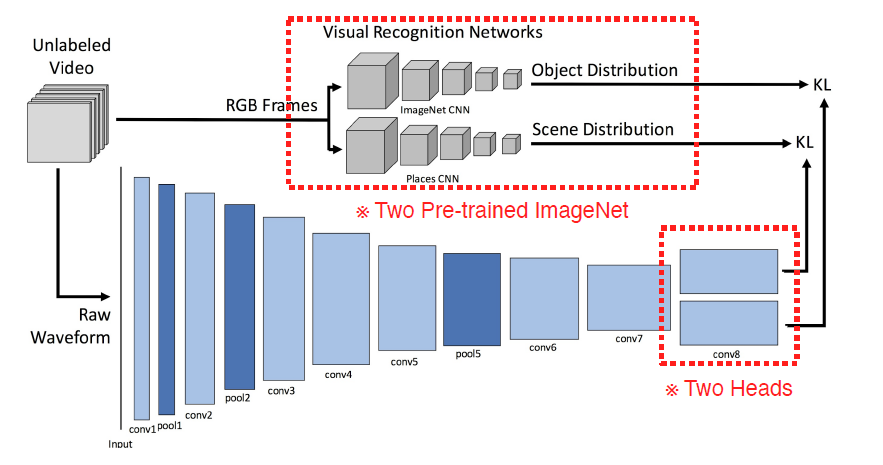
1. Matching : scene recognition by sound, soundNet
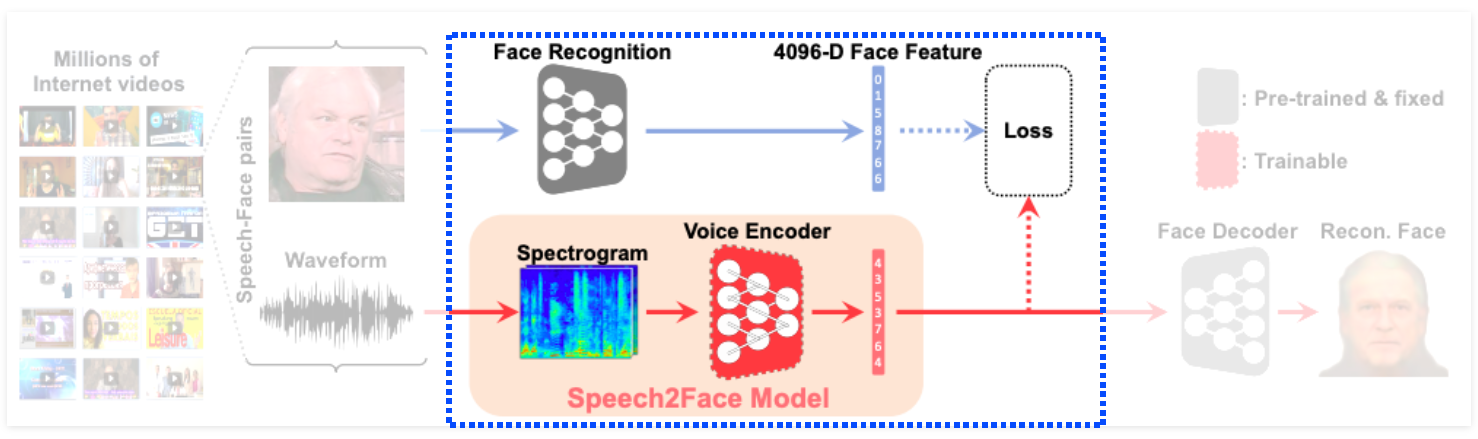
Translating : Speech2Face, Image to sound
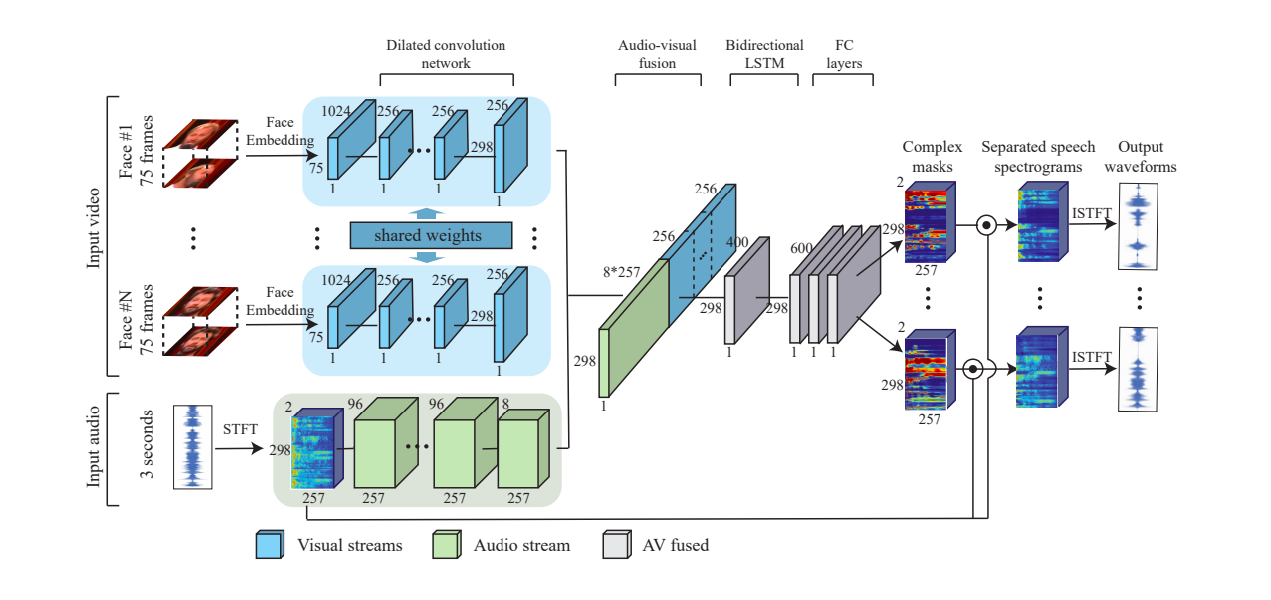
Reasoning : Sound source localization, cocktail party









댓글