목차
1. 강의정리
1-1. CV - chap1. Image Classification 1
2. 과제
2-1. Assignment1_blank.ipynb (vgg11)
3. 피어세션 정리
4. 데일리 회고

📜 강의 정리
[CV] Chapter1. Image classification 1
- 컴퓨터비전은 왜 인공지능일까?
- 인공지능의 정의를 살펴보면, 인간의 지능을 모방하는 것이다. 컴퓨터비전은 사람의 눈을 대신하는 기술이기 때문에 인공지능이라고 할 수 있다.
- 이상적인 이미지 인식 방법은 세상의 모든 이미지를 학습시키고 k-nn 방식으로 비슷한 이미지를 고르는 것이지만, 모든 데이터를 학습시키는 것도 어렵고 모든 데이터에 대한 비교를 하는 것도 현실적이지 않다.
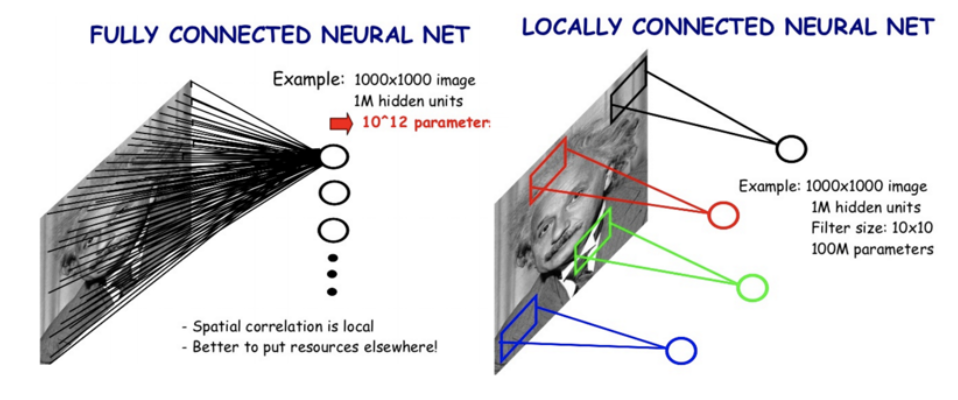
- Single fully connected layer의 문제점

- Convolutional Neural Network(CNN)으로 위의 문제를 해결할 수 있다. Fully → Locally connected NN
- CNN is used as a backbone of many CV tasks
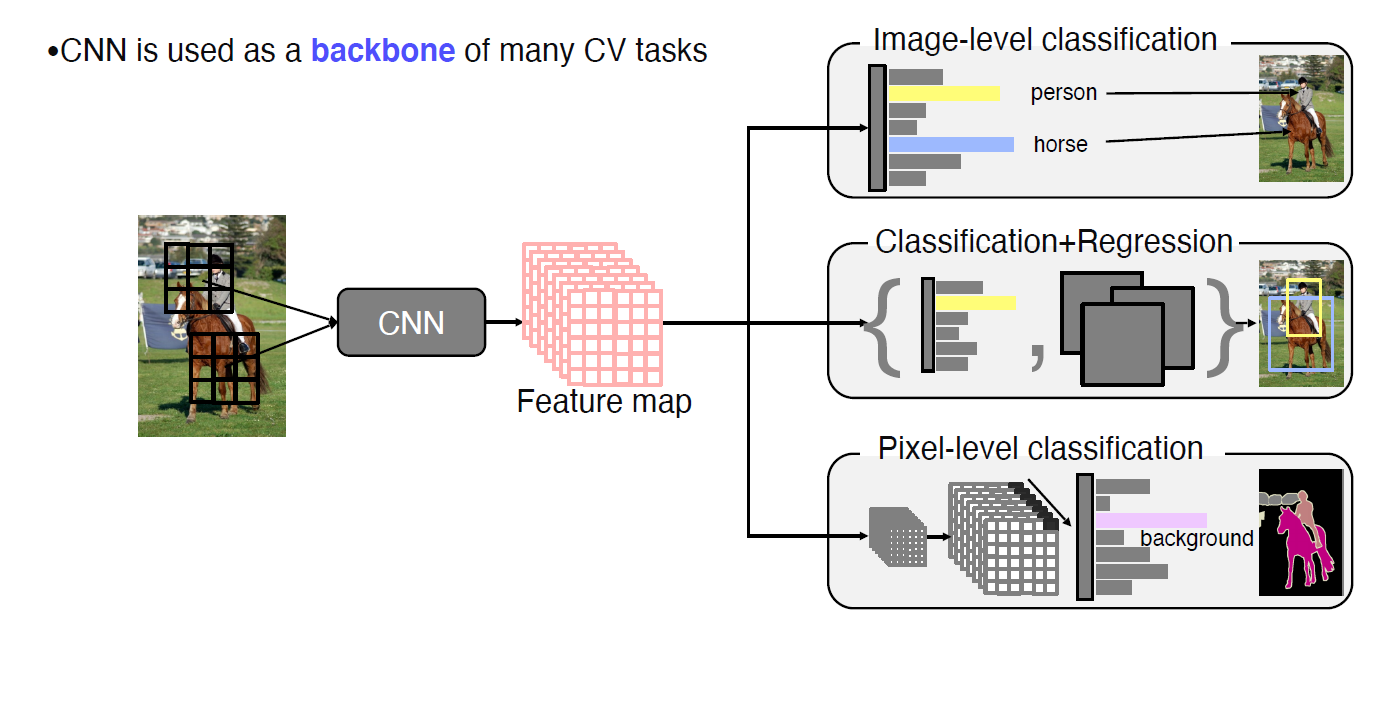
CNN architectures for Image Classification 1
1. AlexNet
- overall architecture
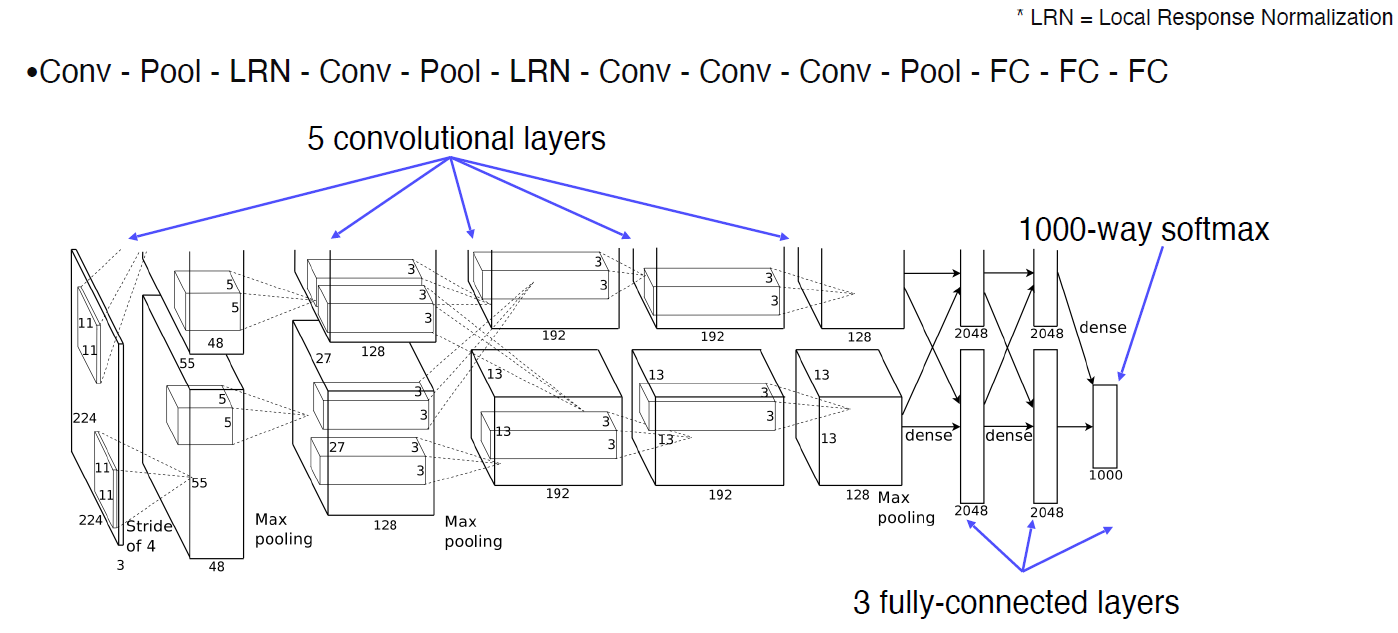

- LRN은 activation map에서 명암을 normalization 하는 기능인데, 최근에는 Batch normalization을 사용하면서 더이상 LRN을 사용하지 않게 되어서 빠지게 되었다.
2. VGG
- AlexNet에 비해 깊고 간단해졌다.
- 모든 커널이 3×3, 맥스 풀링이 2×2라는 특징
- input size가 224×224×3이고, RGB mean값은 빼주어 정규화를 한다.


👩💻 과제 수행 과정

💥 과제내용 : VGG11 구현 및 Fine Tuning
❓ 왜 feature extraction 부분이 끝나고 classificatio으로 넘어가는 부분에서 채널 사이즈가 512*7*7 일까? 512는 채널 개수인데 왜 커널크기는 7일까?
✅ VGG의 input size는 224이고 maxPool2d(kernel_size=2, strides=2)를 수행할 때마다 input size의 크기가 1/2이 된다.
아래의 코드의 주석을 통해 image size의 변화를 볼 수 있다.
import torch
import torch.nn as nn
class VGG11(nn.Module):
def __init__(self, num_classes=10):
super(VGG11, self).__init__()
self.relu = nn.ReLU(inplace=True)
# Convolution Feature Extraction Part
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(64)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 224 → 112
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(128)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) # 112 → 56
self.conv3_1 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.bn3_1 = nn.BatchNorm2d(256)
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn3_2 = nn.BatchNorm2d(256)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2) # 56 → 28
self.conv4_1 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.bn4_1 = nn.BatchNorm2d(512)
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn4_2 = nn.BatchNorm2d(512)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2) # 28 → 14
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn5_1 = nn.BatchNorm2d(512)
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn5_2 = nn.BatchNorm2d(512)
self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2) # 14 → 7
# Fully Connected Classifier Part
self.fc1 = nn.Linear(512*7*7, 4096)
self.dropout1 = nn.Dropout()
self.fc2 = nn.Linear(4096, 4096)
self.dropout2 = nn.Dropout()
self.fc3 = nn.Linear(4096, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.pool2(x)
x = self.conv3_1(x)
x = self.bn3_1(x)
x = self.relu(x)
x = self.conv3_2(x)
x = self.bn3_2(x)
x = self.relu(x)
x = self.pool3(x)
x = self.conv4_1(x)
x = self.bn4_1(x)
x = self.relu(x)
x = self.conv4_2(x)
x = self.bn4_2(x)
x = self.relu(x)
x = self.pool4(x)
x = self.conv5_1(x)
x = self.bn5_1(x)
x = self.relu(x)
x = self.conv5_2(x)
x = self.bn5_2(x)
x = self.relu(x)
x = self.pool5(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout1(x)
x = self.fc2(x)
x = self.relu(x)
x = self.dropout2(x)
x = self.fc3(x)
return x
❓ features 부분만 freeze하고 싶습니다.
✅ model.features.parameters()를 통해 features 부분의 파라미터만 가져올 수 있습니다.
for param in model.features.parameters():
param.requires_grad = False
🔴 그 외 새롭게 배우게 된 점
✅ model_finetune.classifier[6] = nn.Linear(4096, 10) : 이런식으로 classifier layer의 6번째 layer에 접근할 수 있다
✅ 각 layer의 training 여부를 간단하게 확인하고 싶을 때 → named_parameters() 사용
for name, layer in model.named_parameters():
print("=" * 40)
print("%-20s ==> Train : %s" % (name, layer.requires_grad))
'''
< 결과 >
========================================
features.0.weight ==> Train : False
========================================
features.0.bias ==> Train : False
========================================
features.3.weight ==> Train : False
========================================
features.3.bias ==> Train : False
========================================
features.6.weight ==> Train : False
========================================
features.6.bias ==> Train : False
========================================
features.8.weight ==> Train : False
========================================
features.8.bias ==> Train : False
========================================
features.11.weight ==> Train : False
========================================
features.11.bias ==> Train : False
========================================
features.13.weight ==> Train : False
========================================
features.13.bias ==> Train : False
========================================
features.16.weight ==> Train : False
========================================
features.16.bias ==> Train : False
========================================
features.18.weight ==> Train : False
========================================
features.18.bias ==> Train : False
========================================
classifier.0.weight ==> Train : True
========================================
classifier.0.bias ==> Train : True
========================================
classifier.3.weight ==> Train : True
========================================
classifier.3.bias ==> Train : True
========================================
classifier.6.weight ==> Train : True
========================================
classifier.6.bias ==> Train : True
'''
🙋♀️피어세션
피어세션 목표를 설정
- 질문 + 공유를 사정없이 해보는 걸 목표로 진행하자.
- 알고리즘 공부
- 최동민 멘토님의 정리 논문 정리를 읽으면서 -> 피어세션 남은 시간에 시간을 내서 공부해보기 -> 최동민 멘토님께 질문해도 되는지 양해를 구하기
- 당일날 지각하는 사람 -> 커피 같은 벌칙
- tmi 토크을 이용한 ice breaking
- 한번에 다 정하지 않고, 강의량(계획)에 따라 조금 적절히 정하면서 해보자. (강의의 양만큼 정해보자.)
- git에 각자의 브렌치를 만들어서 각자 공부한 것을 올려보자.
- organization 레포 하나 파보자.
💌 Daily 회고
- 부캠 1기수 밋업을 진행했는데 다들 정말 열심히 하는 모습이 멋있었고, 동기부여가 되었다.
- 처음으로 당일에 과제를 제출해서 뿌듯했다
- 오후 11시부터 팀원들이랑 모각공을 했는데 모르는 것들을 공유하는 시간이 좋았다
- 전에 darknet53 구현을 못했었는데, 간단한 vgg부터 연습할 수 있어서 darknet도 다음에 도전해봐야겠다!
'TIL > Boostcamp AI tech' 카테고리의 다른 글
| [Boostcamp lv2]Week7-Day33. Multi-modal Learning :: seoftware (0) | 2021.09.16 |
|---|---|
| [Boostcamp Lv2] Week7-Day30. CNN Visualization :: seoftware (0) | 2021.09.16 |
| [Image Classification] Week5 Daily Report :: seoftware (0) | 2021.09.03 |
| [Boostcamp]Week4-Day18. Training & Inference :: seoftware (0) | 2021.08.26 |
| [Boostcamp]Week4-Day17. Model :: seoftware (0) | 2021.08.25 |



댓글