목차
1. 강의 정리
1-1. AI Math - chap9. CNN 첫걸음
1-2. AI Math - chap10. RNN 첫걸음
2. 과제
2-1. Backpropagation
3. 피어세션 정리
4. 데일리 회고

📜 강의 정리
* 부스트캠프 AI_Math 강의를 맡아주신 임성빈 교수님의 강의를 정리한 것 입니다.
[AI Math] Chapter9. CNN 첫걸음
- Convolution 연산 이해하기
-
- 지금까지 배운 다층신경망(MLP)은 각 뉴런들이 선형모델과 활성함수로 모두 연결된(fully connceted) 구조
- Convolution 연산은 이와 달리 커널(kernel)을 입력벡터 상에서 움직여가면서 선형모델과 합성함수 적용
- 정리하면, i 번째 위치의 가중치 행렬(W(i))이 따로 존재하지 않고 공통된 커널을 사용하여 연산에 활용하기 때문에 파라미터 사이즈를 줄일 수 있다
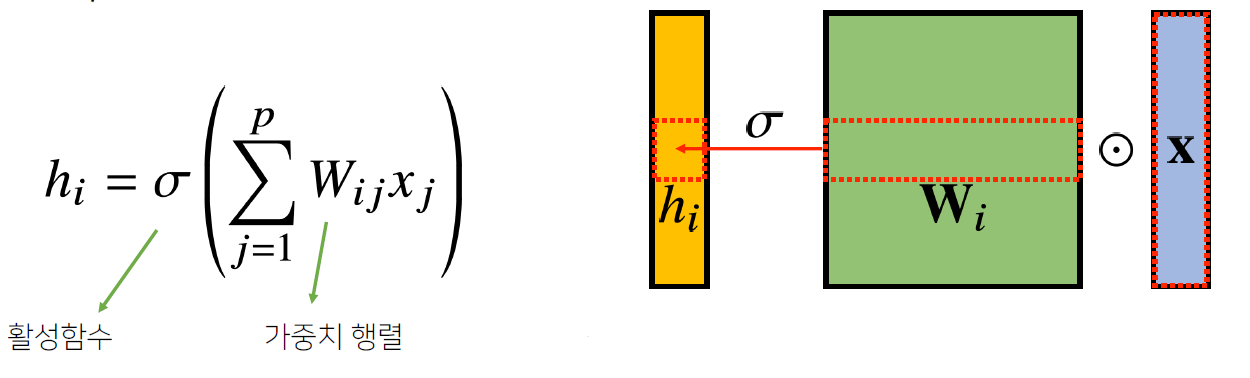
i가 바뀌면 사용되는 가중치 W도 바뀐다 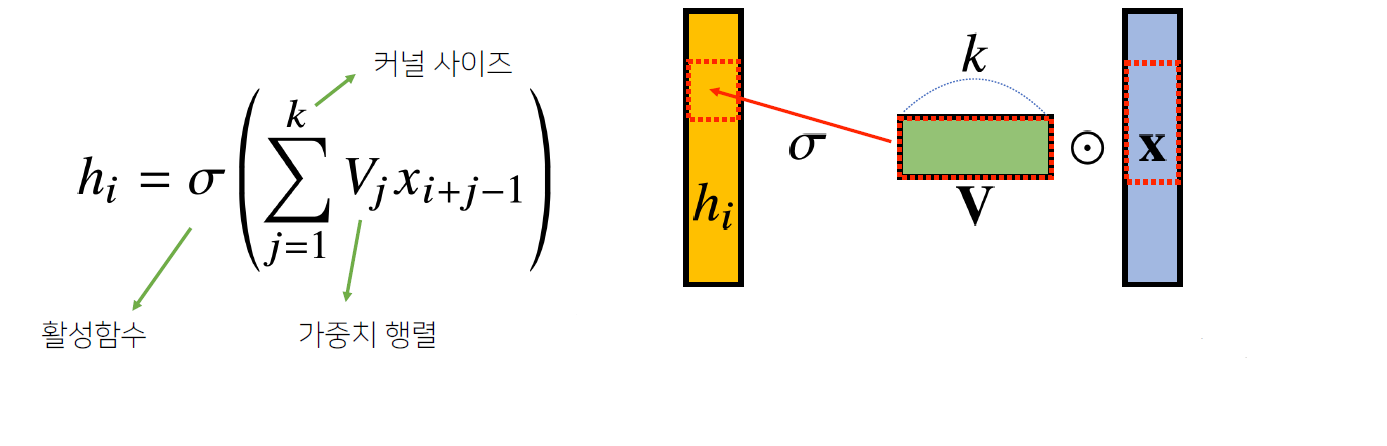
모든 i에 대해 적용하는 커널이 V로 같고 커널의 사이즈만큼 X 상에서 이동하며 적용 - 활성화 함수를 제외한 Convolution 연산도 선형변환에 속한다
-
- Convolution 연산의 수학적인 의미
- 신호(signal)를 커널을 이용해 국소적으로 중폭 또는 감소시켜서 정보를 추출 또는 필터링하는 것
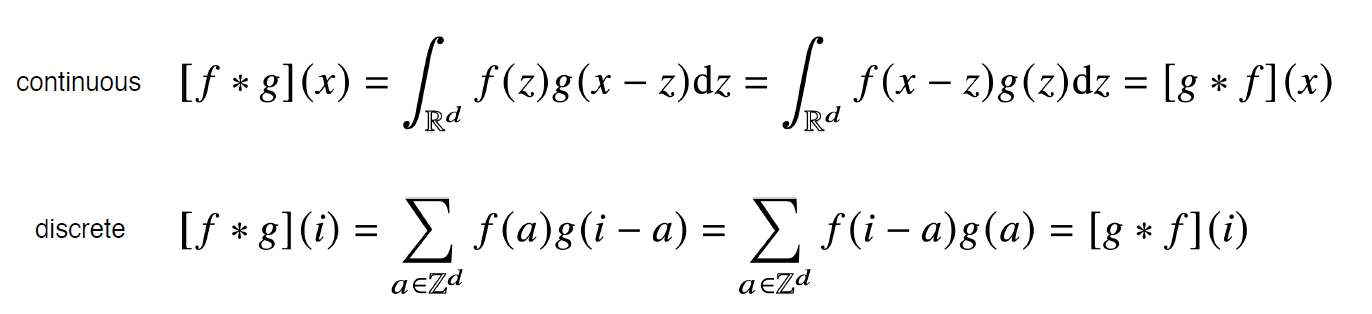
g가 신호, f가 커널 - 커널은 정의역 내에서 움직여도 변하지 않고(translation invariant) 주어진 신호에 국소적(local)으로 적용

신호와 커널에 대한 이해를 돕는 자료
- Convolution 연산의 수학적인 의미
- 다양한 차원에서의 Convolution
- Convolution 연산은 1차원뿐만 아니라 다양한 차원에서 계산 가능

- 차원별 사용예 : 1D - 음성, 텍스트 / 2D - 흑백 영상 / 3D - 컬러 영상
- 커널 f가 위치에 따라 바뀌지 않는다는 점이 convolution 연산의 핵심
- 2차원 Convolution 연산
- 2D-Conv 연산은 커널을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조입니다.
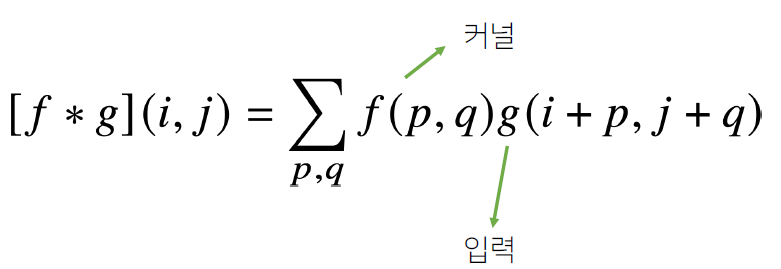
-
- 입력 크기를 (H, W), 커널 크기를 (K_h, K_w), 출력 크기를 (O_h, O_w) 라고 할 때 출력 크기 계산
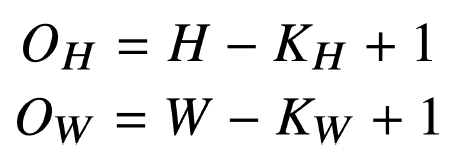
- 채널이 여러개인 2차원 입력(3차원 - 텐서)의 경우 2차원 Convolution을 채널 개수만큼 적용한 후 모두 더함
- 채널 개수 == 커널 개수

- 위에서 커널을 O_c 개를 사용하면 출력도 (O_h, O_w, O_c)의 텐서 형태가 된다
- 입력 크기를 (H, W), 커널 크기를 (K_h, K_w), 출력 크기를 (O_h, O_w) 라고 할 때 출력 크기 계산
- Convolution 연산의 역전파
- Convolution 연산은 커널이 모든 입력데이터에 공통으로 적용되기 때문에 역전파를 계산할 때도 Convolution 연산이 나오게 된다.

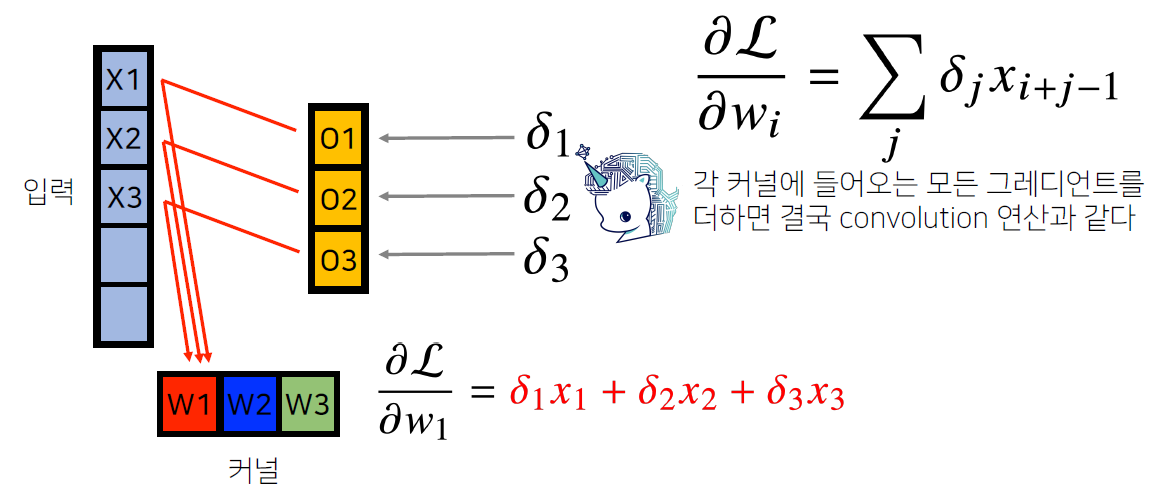
discrete에도 똑같이 적용 - 그림으로 이해하면 훨씬 쉬움
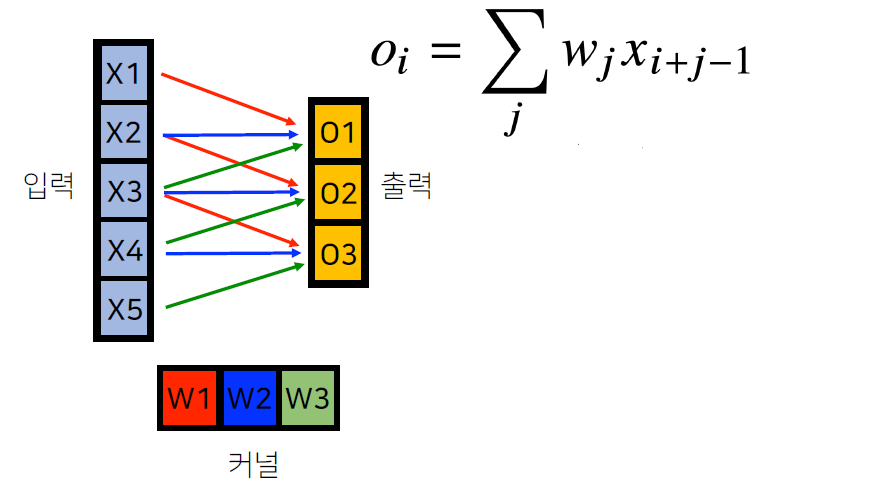
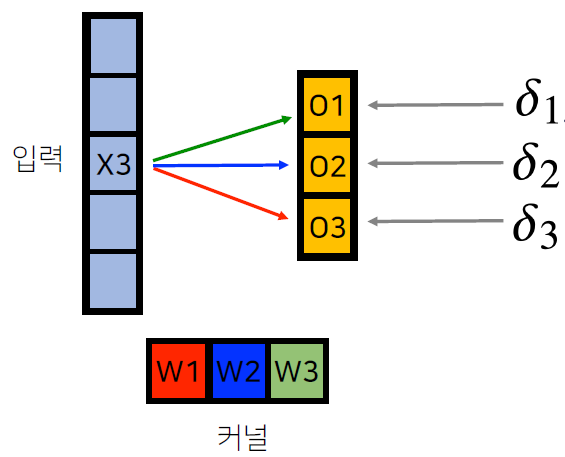
- 어떤 X와 W가 각 O에 영향을 주는지 확인
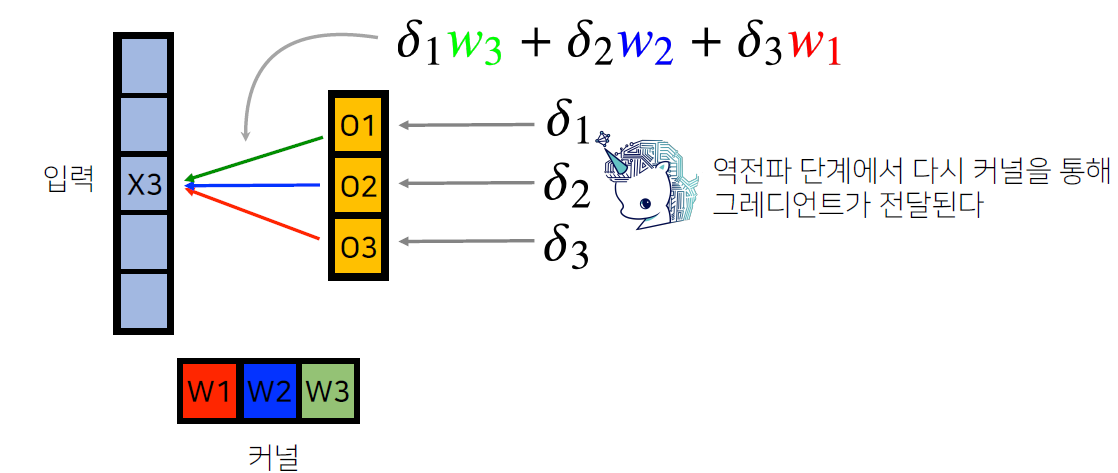
- X3은 W3 커널과 곱해져서 O1에 갔고, W2 커널과 곱해져서 O2에 갔고, W1 커널과 곱해져서 O3에 감
- O = W*X 이므로 O를 X로 편미분하면 W이므로 X에 O*W로 값을 업데이트
- 마찬가지로, O를 W로 편미분하면 X이므로 W에 O*X로 값을 업데이트
- 모든 값에 대해 적용
- 어떤 X와 W가 각 O에 영향을 주는지 확인

[AI Math] Chapter10. RNN 첫걸음
- 시퀀스 데이터
- 소리, 문자열, 주가 등의 데이터를 시퀀스(sequence) 데이터로 분류
- 시퀀스 데이터는 독립동등분포 가정을 잘 위배하기 때문에 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 된다.
- 예시) "개가 사람을 물었다"와 "사람이 개를 물었다"
- 시퀀스 데이터 다루는 방법
- 이전 시퀀스의 정보를 가지고 앞으로 발생할 데이터의 확률분포를 다루기 위해 조건부확률 이용 가능
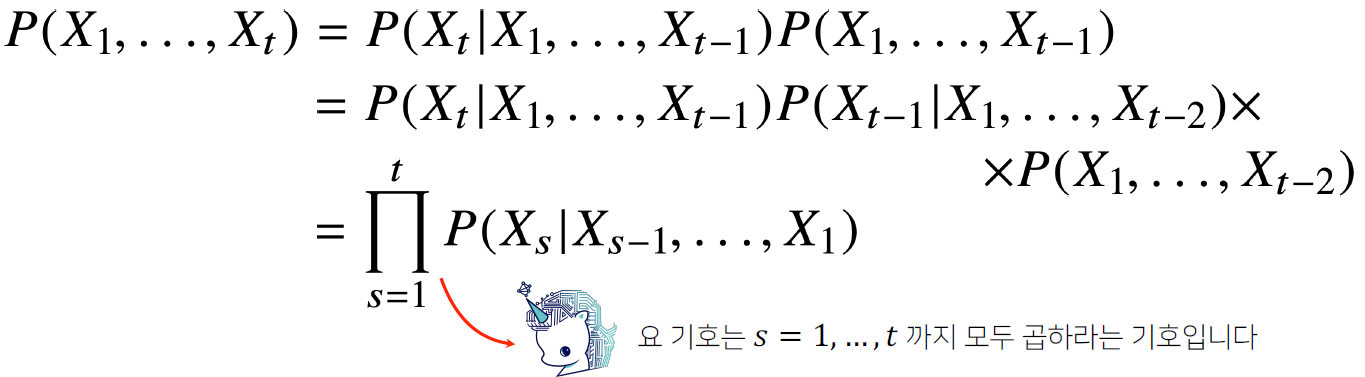
조건부확률로 시퀀스데이터 다루기 - 과거의 모든 정보를 사용하지만 시퀀스 데이터를 분석할 때 모든 과거 정보들이 필요한 것은 아니다.
- 시퀀스 데이터를 다루기 위해선 길이가 가변적인 데이터를 다룰 수 있는 모델이 필요하다
- AR(τ) - Autoregressive Model 자기회귀모델 : 고정된 길이 τ(타우) 만큼의 시퀀스만 사용하는 경우
- 잠재 AR 모델 : 직전 정보(X(t-1))와 X(t-1) 이전의 정보를 H(t)라는 잠재변수로 인코딩해서 활용. 길이가 가변적이지 않고 고정적. 과거의 모든 정보를 인코딩하는게 문제인데, 이걸 해결하기 위한 방법이 RNN!
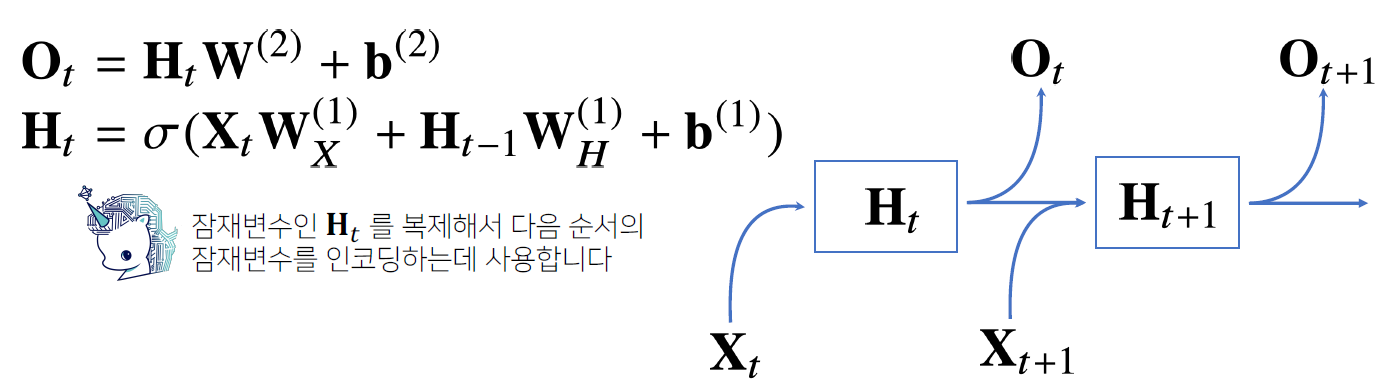
- Recurrent Neural Network
- 가장 기본적인 RNN 모형은 MLP와 유사한 모양

MLP 모델로는 과거의 정보를 다룰 수 없음
- RNN은 이전 순서의 잠재변수와 현재의 입력을 활용하여 모델링
- RNN 역전파는 잠재변수의 연결그래프에 따라 순차적으로 계산
- Backpropagation Through Time(BPTT)
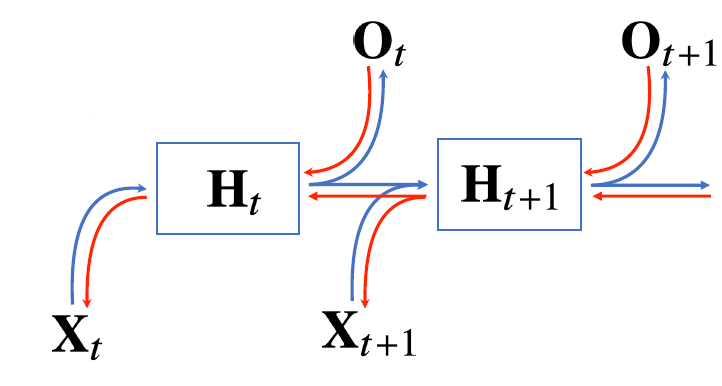
입출력이 2개씩 
BPTT 미분계산
- Backpropagation Through Time(BPTT)
- 기울기 소실의 해결책
- truncated BPTT : BPTT를 통한 역전파 알고리즘의 계산이 불안정해지므로 길이를 끊는 것
- LSTM, GRU의 방법도 있다.
- 가장 기본적인 RNN 모형은 MLP와 유사한 모양
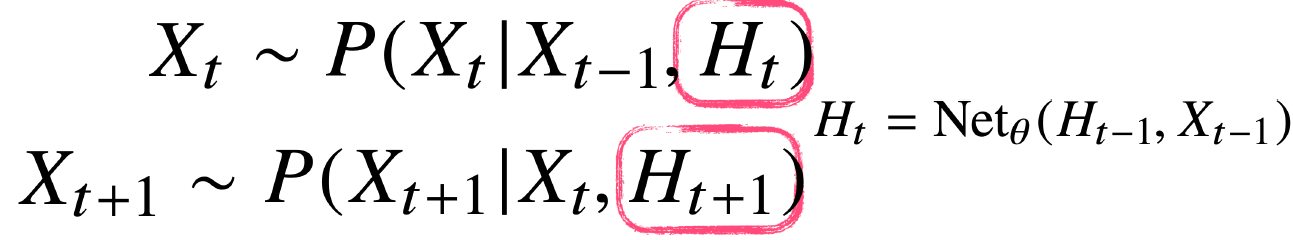

👩💻 과제 수행 과정
[선택과제] 2. Backpropagation
오늘 들었던 RNN 수업을 복습하는 시간이었다. RNN에서 Backward step으로 gradient를 계산하는 코드를 작성하였다.
처음에는 변수가 무엇을 의미하는지 잘 모르겠었는데, 테스트코드를 보면서 변수가 무엇인지 하나씩 이해했다
아래와 같이 각 노드별로 편미분을 하다 보니 규칙을 발견했다

규칙 1. S_k gradient은 k값이 1씩 작아질 때마다 W_rec이 하나씩 곱해지는 것
규칙 2. W_rec gradient은 S_k gradient에 S_k-1가 곱해지는 것
규칙 3. W_x gradient은 S_k gradient에 X_k-1이 곱해지는 것
위의 규칙에 따라 S와 X의 shape을 맞춰서 코드를 짰더니 통과됐다!!
for k in range(X.shape[1], 0, -1):
wx_grad += np.mean(grad_over_time[:,k] * X[:,k-1])
wRec_grad += np.mean(grad_over_time[:,k] * S[:,k-1])
grad_over_time[:,k-1] = grad_over_time[:,k] * wRec
🙋♀️피어세션
"멘토님 미팅"
- 멘토님과 팀원들의 자기소개
- 각자 학부생/취준생 여부와 부스트캠프 이후 진로에 대해 소개를 했다
- 매주 멘토링 시작은 TMI 시간을 갖기로 했다. 각자 입을 풀기 위해 일주일 동안 있었더 TMI를 하나씩 소개한다
- 멘토님이 도움을 주신다고 하신 것
- [학습관련] Github 협업, 실험관리 세팅, 리눅스, 그 외 프로젝트와 관련된 다양한 기술들
- [커리어관련] 일반적인 취업, 창업, 해외 유학, 해외 취업, 개발자 영어 학습법, 직장없이 커리어 개발
- [기타] 심심하거나 외로울 때, 갑자기 불안할 때, 자랑하고 싶은게 있을 때, 홍대(신촌)에서 잠깐 시간이 빌 때 등
- 새롭게 추가된 피어세션 규칙
- 같이 Leetcode 또는 백준으로 알고리즘 공부하고 코딩 연습하기
- 회의록을 노션에 정리하기
- 수요일 피어세션 시간에 질문 취합해서 멘토님께 보내기
🙋♀️마스터클래스
"임성빈 교수님 - 인공지능과 수학"
Young man, in mathematics you don't understand things. You just get used to them.
- John von Neumann
폰노이만의 "수학은 이해하는 것이 아니라 익숙해지는 것이다"라는 명언으로 마스터 클래스가 시작되었다.
이 말을 듣고 이번 주에 확률&통계에서 패배했던 것을 위로 받고 있었는데, 채팅에서 "YOU"인 것에 집중해서 너무 웃겼다. Not me but you,,, ㅋㅋㅋㅋㅋ 폰노이만은 모든 수학을 이해했던 걸로ㅋㅋㅋㅋㅋㅋㅋㅋㅋ
오늘 강의에서 유용했던 팁들 몇 개를 정리하자면,
- 수학시작 방법
- 일단 용어의 정의를 외워라 : 교과서, 위키피디아
- 만일 용어 사용이 헷갈리면 인공지능 커뮤니티 물어봐라 : AI Korea(Deep Learnig), PyTorch KR, Tensorflow KR
- 용어를 외웠다면 예제를 찾아봐라
- 인공지능 수학의 기초 : 선형대수, 확률론, 통계학 - 이 중 선형대수는 저어어어엉말 기초라고 강조해주셨다
- 도서 추천 : https://d2l.ai/
Dive into Deep Learning — Dive into Deep Learning 0.17.0 documentation
d2l.ai
- 기업에서 대학원생을 선호하는 이유와 학석박의 차이에 대해서도 설명해주셨다. CV 쪽은 다행히 학사도 가능성이 있어보였다. 다만, 논문 구현이 가능한,, 이 분야 논문을 써 본,, 오픈소스 기여 경험이 있는,,,
- 간단한 논문 구현부터 해보라고 하셨는데, 한 번 스터디를 구해봐야겠다.
- Tensorflow 기반의 코드를 Pytorch로 바꾸는 것도 아주 좋다고 하셨다.
마스터클래스 덕분에 무엇을 더 공부해야하는지 어떻게 기초를 쌓아야 하는지 갈래를 잡을 수 있었다.
💌 데일리 회고
어제 피어세션이 피었습니다 시간에 알게된 다른 조의 캠퍼님들과 슬랙톡방이 만들어졌다. 다른 조의 이야기도 들을 수 있고 모르는 질문을 공유할 수 있어서 좋은 방이라고 생각했는데, 오늘 코어타임이 시작하고 끝날 때마다 캠퍼님들께서 시작 인사와 끝 인사를 보내주셨다. 작은 말에 힘이 나고 오늘 하루도 열심히 공부해야지 하는 생각이 들어서 나도 캠퍼님들이 힘을 낼 수 있도록 응원의 메세지를 보냈다 🙌
오전에는 CNN과 RNN에 관한 강의를 들었다. CNN에 대한 이론은 알고 있어서 강의 정리하는데 편했고, RNN은 처음 배우는 이론이었지만 NLP를 배우려면 필수이기 때문에 집중을 해서 들었다. 수학식이 나올 때마다 자괴감이 들었지만, 마스터 클래스 시간에 임성빈 교수님께서 수학을 모두 이해할 수는 없고 수식을 자주 봐서 익숙해지고 사용할 수 있으면 된다는 말에 안심을 하게 되었다.
오후에는 개인과제 시간에는 선택과제를 풀고, 강의를 정리했다. 피어세션 시간을 알차게 보내고 나니 금방 시간이 6시여서 후다닥 마스터클래스 줌으로 옮겨갔다.
제출해야하는 과제가 다 끝나서 마음이 아주 편하다. 오늘은 강의를 정리하고 퀴즈를 풀고 잠에 들어야겠다 ✨
'TIL > Boostcamp AI tech' 카테고리의 다른 글
| [Boostcamp] Week2 - Day6. Neural network :: seoftware (0) | 2021.08.09 |
|---|---|
| [Boostcamp] Week1 - Day5. 하루 정리 :: seoftware (0) | 2021.08.06 |
| [Boostcamp] Week1 - Day3. 하루정리 :: seoftware (0) | 2021.08.05 |
| [Boostcamp] Week1 - Day2. 하루 정리 :: seoftware (0) | 2021.08.05 |
| [Boostcamp] Week 1 - Day 1. 하루 정리 :: seoftware (0) | 2021.08.03 |




댓글